Authors
Muhammad Hilman Beyri (mbeyri), Zixu Ding (zixud)
Final Report
Summary
We have developed a cloud-based CPU (SIMD)/GPU hybrid interactive raytracing demo, using an adaptive load-balancing algorithm which partitions work among nodes without knowing their computing power in advance.
Our goal is to combine multiple levels of parallelism : CPU Multi-threading, SIMD, GPU (CUDA), and distributed computing over multiple nodes to maximize each node's performance and make the ray-tracing application run in real-time.
Achievements
We started with hand-crafting a single-threaded pool table raytracing demo, and parallelized it with CUDA and CPU multi-threaded SIMD. The CUDA version achieves a 181.6x speedup, and the SIMD version has a MEASURING speedup. However, as the speedups on the same node are different, and the ratio of GPU/CPU computing power can also differ across nodes, we decided to implement a general heterogeneous load-balancing algorithm, which estimates a computing device's overall response time as a function of workload: y = f(x). Using different functions to estimate results in different load-balancing algorithms. We will give details of different algorithms we have tried in the following section.
Load Balancer
We created several load balancer algorithm.
-
Equal Division
In the beginning of the program, for a certain number of frame, dracuda will divide the workload equally to all nodes. This is because dracuda doesn't yet know anything about the connected nodes.
-
Naive Division
This is our first stab of implementing load balancer. We end up not using this. This algorithm will simply give bigger workload to node with smaller response time, which we know from the previous frame. This algorithm is prone to sudden change of node's response time.
-
AB Division
We realize we can't just rely on the previous frame's information. We collect for each slave, their average network latency and their average rendering factor. Rendering factor is value we got from dividing rendering latency (the slaves send the rendering latency info to master) with the workload. So bigger rendering factor means slower compute capability.
The slave's response time could be computed with : y = A * Bx. With A is the slave's average network latency (we assume it is not influenced by the workload), B is the slave's average rendering factor, and x is the workload. The goal of the algorithm is to find the same y for all slaves by varying the x for each slaves. The algorithm runs with O(n) time.
For monday presentation, we will create a better grapth to illustrate the data, but for now, we have these data :
Machines :
- ghc41 : NVIDIA GTX 780 GPU
- ghc42, ghc43, ghc32, ghc33 : NVIDIA GTX 670 GPU
2 Slaves, ghc41 & ghc42 (NVIDIA GTX) :
-
Load Balancing Off (Equal Division):
GHC41 Response time :0.0235545 Rendering latency: 0.0133358 Average rendering factor: 4.63063e-05 GHC42 Response time: 0.0330588 Average network latency: 0.0131452 Average rendering factor: 6.59128e-05
-
AB division :
GHC41 Response time: 0.0332405 Rendering latency: 0.0166288 Average rendering factor: 4.68121e-05 GHC42 Response time: 0.0302952 Rendering latency: 0.0164119 Average rendering factor: 6.67132e-05
As you can see from the comparison, we are able to balance the rendering latency but the more powerful machine has longer network latency now because of the larger output data. A good compression of the slave's output could potentially improve the network latency.
In more connected slaves setting, network latency has less influence over slave's response time. This is where the AB division starts to shine. Here are the data :
-
Slaves: ghc41, ghc42, ghc43, ghc32, ghc33
-
Load Balancing Off (Equal Division):
Average response time from all slaves: 0.2198242
Standard deviation: 0.051974
-
AB division :
Average response time from all slaves: 0.003849752
Standard Deviation: 0.001124
-
Load Balancing Off (Equal Division):
You can see the comparison of the above algorithms overtime here (5 slaves, ghc41, ghc26, ghc45, ghc30, ghc46) :
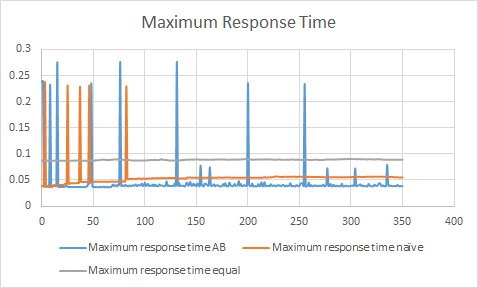
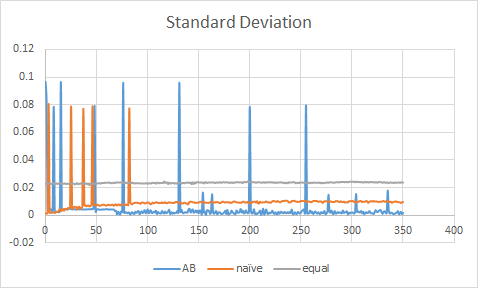
Maximum response time is the maximum of all the response time we have each frame from all slaves. The standard deviation chart shows the standard deviation of the response time from all slaves each frame.
The above chart prove that we have achieved real-time performance with a good workload balance on heterogenous computers.
Background
In computer graphics, ray tracing is a technique for generating an image by tracing the path of light through pixels in an image plane and simulating the effects of its encounters with virtual objects. As such, ray tracing is able to simulate necessary effects to create photorealistic images. However, a high-quality ray tracing can take very long time to render, and is not suitable for real-time applications.
Essential operations in ray tracing, such as intersection tests, transformations, vector math and shading are all data-parallel operations, and therefore are SIMD friendly. Making use of SIMD processors like GPU or CPU SIMD instructions can immensely improve the speed of raytracing.
Many computers nowadays have both CPU and GPU installed. However, most of the time they are idle or poorly utilized. To extract maximum performance from a node, using both the CPU and GPU on the same node is definitely better than using either of them.
With the advent of cloud computing, it is possible to access massive computing resources without actually purchasing them. Even GPU computing instances have become available in the past few years. Therefore, with enough cloud instances, real-time rendering is possible without sacrificing the quality.
Load balancing across heterogeneous nodes can be difficult. That is largely due to the differences of network latency and GPU performance among nodes. In order to balance the overall latency, which we estimate as network latency + work load * rendering time per unit work load, we will gather the rendering time and latency from worker nodes, and use an adaptive linear regression algorithm to predict the network latency and unit rendering time of next frame, and then assign the work load of each node accordingly.
The architecture of this project is simple. Worker nodes are responsible for rendering. They take scene data and the work assignment information (like from Row A - Row B) as input, and send back the rendered portion of the image (compressed). The local client divides the screen into tiles, sends the scene data and work allocation to worker nodes, and collects all the image parts from worker nodes and display the frames. It also adjusts the work assignment each frame using the adaptive algorithm we mentioned above.
Checkpoint Report April 19
The Challenge
Performance
- Network Latency. The latency from Pittsburgh to Amazon US East server is 23 ms. A round-trip would be 46 ms. For a player to not experience lag, the latency has to be below 100 ms, so that restricts the rendering time under 50 ms. Besides, we are aiming for a frame rate of at least 30 FPS, so our goal is to limit the rendering time of each frame to below 33 ms, to ensure the throughput is enough for the 30 FPS experience.
- Load Balancing Algorithm. Different compute nodes have different rendering performance and network latency. Therefore it is challenging to balance the overall latency of all nodes. We will continuously gather analytics data from nodes to adaptively balance the latency.
- Efficient GPU and CPU-SIMD ray tracing implementation. Even though ray tracing is highly parallelizable, there are branch divergences in intersection tests, refraction / reflections, which can cause huge performance slowdown if not handled properly.
- Photorealistic Rendering. To make the rendering as pretty as possible, some effects like caustics, subsurface scattering, diffuse reflection are both difficult to simulate and computationally intensive.
Resources
We have taken 15-662 Computer Graphics and developed a ray tracer on CPU. We will write a single-threaded hardcoded version of the pool scene, and parallelize it using both CUDA and multi-threaded SIMD. During the development, we will use GHC clusters with GPU to test. We will also make sure it works on Amazon EC2, and will run the demo game on it.
Goals and Deliverables
We plan to achieve:
- Distributed parallel ray tracing using CUDA
- Load balancer algorithm that adapts to the network latency and worker nodes' computation time
- API to create distributed ray tracing application
- A game as an example of one of the ray tracing application
- Analysis of the performance of the ray tracer. We hope to achieve real time performance with high quality images
- Particle simulation using material point method
- Subsurface scattering
- CPU and GPU Hybrid parallelization
Platform Choice
We are using CUDA and C++ as our main programming language. The client will be a thin client application using SDL and OpenGL. The client will communicate with other worker nodes using a network protocol that we are going to design. We chose to assume the worker nodes have GPUs that support CUDA.
Schedule
- April 10: Implemented working GPU ray tracer with basic intersection tests and lighting
- April 13: Integrated external physics simulation code for demo
- April 18: Created pool scene and implemented appropriate lighting and materials
- April 23: Design and implementation of the communication protocol between client and server (Hilman)
- April 23: Ray tracer optimization and develop the demo scene (Zixu)
- April 27: Load balancing algorithm design and tuning (Zixu and Hilman)
- May 1: Implement a lossless compression algorithm to reduce the network and IO overhead for transferring the image (Zixu)
- May 1: Deployment on Amazon EC2 GPU instances, and heterogeneous GHC machines to evaluate performance (Hilman)
- May 5: Final parameter tuning according to testing result, write final report and presentation
- Monday, May 9: Presentation